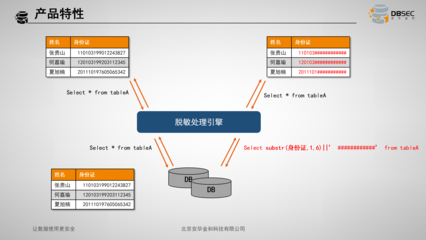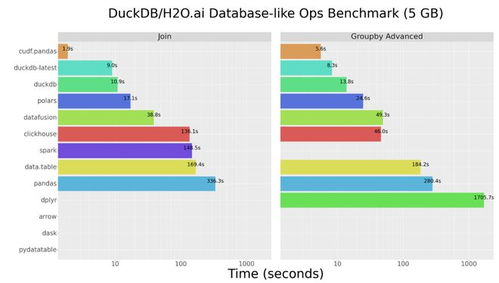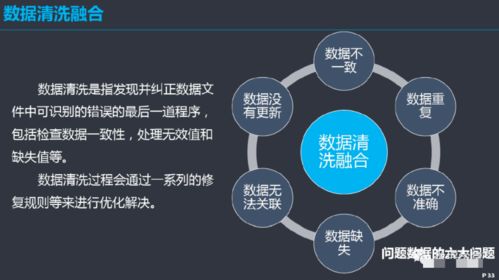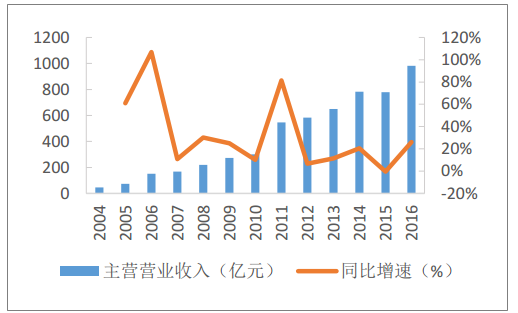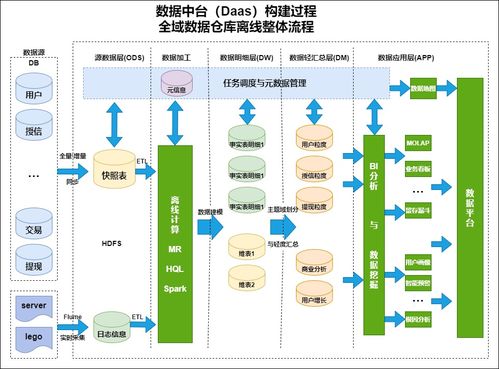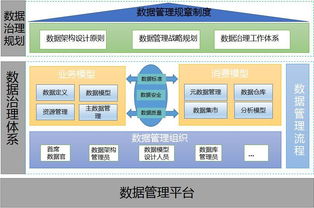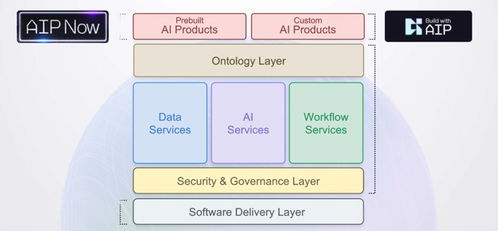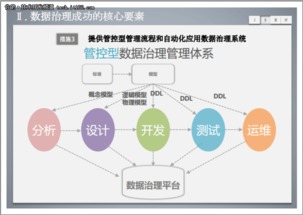
在數字化轉型的浪潮中,數據已成為企業的核心資產。有效的數據治理是確保數據資產價值最大化的基石,而數據模型管控與數據處理,正是這一基石中兩根至關重要的支柱。它們共同定義了數據的形態、流向、質量與應用方式,為企業的數據驅動決策提供堅實保障。
一、數據模型管控:構建清晰的數據藍圖
數據模型是數據的抽象表示,它定義了數據的結構、關系、約束與含義,如同建筑的藍圖。一個科學、統一的數據模型管控方案,能夠確保數據在產生、存儲、流轉和使用過程中的一致性、準確性與可理解性。
1. 管控目標與原則
- 標準化:建立企業級的數據標準與規范,統一業務術語、數據定義、編碼規則等,消除部門間的數據孤島與理解歧義。
- 一致性:確保概念模型、邏輯模型與物理模型在不同系統、不同階段保持內在邏輯的一致,支撐端到端的數據貫通。
- 可維護性與可擴展性:設計靈活、模塊化的模型結構,能夠敏捷響應業務變化與技術演進。
- 業務驅動:模型設計需緊密貼合業務流程與業務需求,確保數據能夠有效服務于業務目標。
2. 管控流程與組織
- 建立治理組織:成立數據治理委員會或數據架構師團隊,負責模型標準的制定、評審、發布與監督執行。
- 全生命周期管理:涵蓋模型的需求調研、設計、評審、發布、部署、變更與退役的全過程。建立嚴格的版本控制和變更管理流程。
- 工具平臺支撐:采用專業的數據建模工具(如ERWin, PowerDesigner等)或數據治理平臺,實現模型的集中存儲、可視化、版本對比與影響分析。
二、數據處理:實現數據價值的引擎
數據處理是指對數據進行采集、清洗、轉換、集成、計算與分析等一系列操作,將原始數據轉化為可信、可用、有價值的信息和知識。它是在數據模型定義的框架下,讓數據“動”起來并產生價值的關鍵過程。
1. 核心處理環節
- 數據采集與集成:從多源異構系統(如業務系統、IoT設備、外部數據源)中抽取數據,并按照目標模型進行整合,形成統一的數據視圖。
- 數據清洗與質量提升:識別并處理數據中的錯誤、缺失、不一致與重復等問題,建立數據質量監控規則與閉環改進機制。
- 數據轉換與加工:根據業務規則和計算邏輯,對數據進行聚合、關聯、衍生等操作,生成指標、標簽、特征等增值數據。
- 數據服務與分發:通過API、數據服務層、數據倉庫/湖倉一體等平臺,將處理好的數據安全、高效地提供給下游的分析、應用與決策系統。
2. 關鍵技術與架構
- 批流一體處理:結合批量處理(如Hadoop, Spark)與實時流處理(如Flink, Kafka Streams)能力,滿足不同時效性的業務需求。
- 數據管道自動化:利用工作流調度工具(如Airflow, DolphinScheduler)實現數據處理任務的編排、監控與自動化執行。
- 數據血緣與可觀測性:建立端到端的數據血緣圖譜,清晰追蹤數據的來源、處理過程與去向,支持影響分析、根因追溯與合規審計。
三、協同聯動:模型管控與數據處理的融合
數據模型管控與數據處理并非孤立存在,而是緊密耦合、相互促進。
- 模型指導處理:清晰、穩定的數據模型為數據處理提供了準確的目標和路線圖。處理流程的設計、轉換規則的制定,都必須嚴格遵循已定義的模型標準,確保產出數據符合預期。
- 處理反饋模型:數據處理過程中暴露的數據質量問題、性能瓶頸或新的業務需求,會反過來推動數據模型的優化與迭代。例如,頻繁的跨表關聯可能提示需要調整模型設計以提升性能。
- 統一治理平臺:理想的數據治理體系應將模型管控(設計、資產目錄)與數據處理(質量、血緣、任務調度)能力整合在統一的平臺或中臺上,實現元數據、數據標準、數據質量、數據安全的聯動管理,形成治理閉環。
###
數據模型管控方案與高效的數據處理流程,共同構成了企業數據治理的“任督二脈”。前者構建了清晰、穩定的數據骨架,后者賦予了數據流動與增值的生命力。只有將兩者系統性地規劃、嚴謹地執行并持續優化,才能將海量、無序的原始數據,轉化為高質量、高可信度、易于使用的戰略性資產,最終賦能業務創新與智能決策,在數字競爭中贏得先機。